使用 Eland 进行在线零售分析#
![]()
了解如何使用 Eland 分析一些在线零售数据。
安装并导入包#
[3]:
!pip install eland
!pip install elasticsearch
from elasticsearch import Elasticsearch
import eland as ed
import getpass
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Fix console size for consistent test results
from eland.conftest import *
Collecting eland
Downloading eland-8.11.1-py3-none-any.whl (157 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 157.9/157.9 kB 3.2 MB/s eta 0:00:00
Collecting elasticsearch<9,>=8.3 (from eland)
Downloading elasticsearch-8.11.1-py3-none-any.whl (412 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 412.8/412.8 kB 8.3 MB/s eta 0:00:00
Requirement already satisfied: pandas<2,>=1.5 in /usr/local/lib/python3.10/dist-packages (from eland) (1.5.3)
Requirement already satisfied: matplotlib>=3.6 in /usr/local/lib/python3.10/dist-packages (from eland) (3.7.1)
Requirement already satisfied: numpy<2,>=1.2.0 in /usr/local/lib/python3.10/dist-packages (from eland) (1.23.5)
Requirement already satisfied: packaging in /usr/local/lib/python3.10/dist-packages (from eland) (23.2)
Collecting elastic-transport<9,>=8 (from elasticsearch<9,>=8.3->eland)
Downloading elastic_transport-8.11.0-py3-none-any.whl (59 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 59.8/59.8 kB 7.6 MB/s eta 0:00:00
Requirement already satisfied: contourpy>=1.0.1 in /usr/local/lib/python3.10/dist-packages (from matplotlib>=3.6->eland) (1.2.0)
Requirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.10/dist-packages (from matplotlib>=3.6->eland) (0.12.1)
Requirement already satisfied: fonttools>=4.22.0 in /usr/local/lib/python3.10/dist-packages (from matplotlib>=3.6->eland) (4.47.0)
Requirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.10/dist-packages (from matplotlib>=3.6->eland) (1.4.5)
Requirement already satisfied: pillow>=6.2.0 in /usr/local/lib/python3.10/dist-packages (from matplotlib>=3.6->eland) (9.4.0)
Requirement already satisfied: pyparsing>=2.3.1 in /usr/local/lib/python3.10/dist-packages (from matplotlib>=3.6->eland) (3.1.1)
Requirement already satisfied: python-dateutil>=2.7 in /usr/local/lib/python3.10/dist-packages (from matplotlib>=3.6->eland) (2.8.2)
Requirement already satisfied: pytz>=2020.1 in /usr/local/lib/python3.10/dist-packages (from pandas<2,>=1.5->eland) (2023.3.post1)
Requirement already satisfied: urllib3<3,>=1.26.2 in /usr/local/lib/python3.10/dist-packages (from elastic-transport<9,>=8->elasticsearch<9,>=8.3->eland) (2.0.7)
Requirement already satisfied: certifi in /usr/local/lib/python3.10/dist-packages (from elastic-transport<9,>=8->elasticsearch<9,>=8.3->eland) (2023.11.17)
Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.10/dist-packages (from python-dateutil>=2.7->matplotlib>=3.6->eland) (1.16.0)
Installing collected packages: elastic-transport, elasticsearch, eland
Successfully installed eland-8.11.1 elastic-transport-8.11.0 elasticsearch-8.11.1
Requirement already satisfied: elasticsearch in /usr/local/lib/python3.10/dist-packages (8.11.1)
Requirement already satisfied: elastic-transport<9,>=8 in /usr/local/lib/python3.10/dist-packages (from elasticsearch) (8.11.0)
Requirement already satisfied: urllib3<3,>=1.26.2 in /usr/local/lib/python3.10/dist-packages (from elastic-transport<9,>=8->elasticsearch) (2.0.7)
Requirement already satisfied: certifi in /usr/local/lib/python3.10/dist-packages (from elastic-transport<9,>=8->elasticsearch) (2023.11.17)
连接到 Elasticsearch#
首先,我们需要连接到一个正在运行的 Elasticsearch 实例。在本例中,我们将使用 Elastic Cloud。注册一个 免费试用。
如果您想连接到一个自管理的集群,请参阅 文档。
[4]:
# Connect to an Elastic Cloud instance
ELASTIC_CLOUD_ID = getpass.getpass("Cloud ID:")
ELASTIC_CLOUD_PASSWORD = getpass.getpass("`elastic` user password:")
es = Elasticsearch(
cloud_id=ELASTIC_CLOUD_ID,
basic_auth=("elastic", ELASTIC_CLOUD_PASSWORD)
)
print(es.info())
Cloud ID:··········
`elastic` user password:··········
{'name': 'instance-0000000001', 'cluster_name': '69662f53fe844e2d81effcbc7f41e867', 'cluster_uuid': 'GHyCC4NpTAC3SyxZkx65Jw', 'version': {'number': '8.12.0-SNAPSHOT', 'build_flavor': 'default', 'build_type': 'docker', 'build_hash': '38ddf39a3efc422a702adc83b1bb2cd6fc2edc5b', 'build_date': '2024-01-03T12:58:40.771552945Z', 'build_snapshot': True, 'lucene_version': '9.9.1', 'minimum_wire_compatibility_version': '7.17.0', 'minimum_index_compatibility_version': '7.0.0'}, 'tagline': 'You Know, for Search'}
下载测试数据#
让我们从下载测试数据开始。
[5]:
import requests
# URL of the raw file on GitHub
file_url = "https://github.com/elastic/eland/raw/main/docs/sphinx/examples/data/online-retail.csv.gz"
# Local path where you want to save the file
local_filename = "online-retail.csv.gz"
# Send a GET request to the file URL
response = requests.get(file_url, stream=True)
# Open a local file in binary write mode
with open(local_filename, 'wb') as file:
for chunk in response.iter_content(chunk_size=128):
file.write(chunk)
print(f"File downloaded: {local_filename}")
File downloaded: online-retail.csv.gz
创建 Eland 数据帧#
首先,让我们通过读取 CSV 文件创建一个 eland.DataFrame。这将在本地 Elasticsearch 集群中创建并填充 online-retail 索引。
[6]:
df = ed.csv_to_eland("online-retail.csv.gz",
es_client=es,
es_dest_index='online-retail',
es_if_exists='replace',
es_dropna=True,
es_refresh=True,
compression='gzip',
index_col=0)
/usr/local/lib/python3.10/dist-packages/eland/etl.py:529: FutureWarning: the 'mangle_dupe_cols' keyword is deprecated and will be removed in a future version. Please take steps to stop the use of 'mangle_dupe_cols'
reader = pd.read_csv(filepath_or_buffer, **kwargs)
/usr/local/lib/python3.10/dist-packages/eland/etl.py:529: FutureWarning: The squeeze argument has been deprecated and will be removed in a future version. Append .squeeze("columns") to the call to squeeze.
reader = pd.read_csv(filepath_or_buffer, **kwargs)
在这里,我们看到 "_id" 字段被用来索引我们的数据帧。
[7]:
df.index.es_index_field
[7]:
'_id'
接下来,我们可以检查 Elasticsearch 中哪些字段可用于我们的 Eland 数据帧。在实例化数据帧时,可以将 columns 作为参数传递,这样可以只选择索引中的一部分字段包含在数据帧中。由于我们没有设置此参数,因此我们可以访问所有字段。
[8]:
df.columns
[8]:
Index(['Country', 'CustomerID', 'Description', 'InvoiceDate', 'InvoiceNo', 'Quantity', 'StockCode',
'UnitPrice'],
dtype='object')
现在,让我们看看我们的字段的数据类型。运行 df.dtypes,我们可以看到 Elasticsearch 字段类型是如何映射到 Pandas 字段类型的。
[9]:
df.dtypes
[9]:
Country object
CustomerID float64
Description object
InvoiceDate object
InvoiceNo object
Quantity int64
StockCode object
UnitPrice float64
dtype: object
我们还提供了一个 .es_info() 数据帧方法,该方法显示了关于底层索引的所有信息。它还包含有关从数据帧方法传递到 Elasticsearch 的操作的信息。稍后会详细介绍。
[10]:
print(df.es_info())
es_index_pattern: online-retail
Index:
es_index_field: _id
is_source_field: False
Mappings:
capabilities:
es_field_name is_source es_dtype es_date_format pd_dtype is_searchable is_aggregatable is_scripted aggregatable_es_field_name
Country Country True keyword None object True True False Country
CustomerID CustomerID True double None float64 True True False CustomerID
Description Description True keyword None object True True False Description
InvoiceDate InvoiceDate True keyword None object True True False InvoiceDate
InvoiceNo InvoiceNo True keyword None object True True False InvoiceNo
Quantity Quantity True long None int64 True True False Quantity
StockCode StockCode True keyword None object True True False StockCode
UnitPrice UnitPrice True double None float64 True True False UnitPrice
Operations:
tasks: []
size: None
sort_params: None
_source: ['Country', 'CustomerID', 'Description', 'InvoiceDate', 'InvoiceNo', 'Quantity', 'StockCode', 'UnitPrice']
body: {}
post_processing: []
选择和索引数据#
现在我们已经了解了如何创建数据帧并访问它的底层属性,让我们看看如何选择数据的子集。
头和尾#
与 Pandas 非常相似,Eland 数据帧提供 .head(n) 和 .tail(n) 方法,分别返回前 n 行和后 n 行。
[11]:
df.head(2)
[11]:
| 国家 | 客户 ID | ... | 库存代码 | 单价 | |
|---|---|---|---|---|---|
| 0 | 英国 | 17850.0 | ... | 85123A | 2.55 |
| 1 | 英国 | 17850.0 | ... | 71053 | 3.39 |
2 行 × 8 列
[12]:
print(df.tail(2).head(2).tail(2).es_info())
es_index_pattern: online-retail
Index:
es_index_field: _id
is_source_field: False
Mappings:
capabilities:
es_field_name is_source es_dtype es_date_format pd_dtype is_searchable is_aggregatable is_scripted aggregatable_es_field_name
Country Country True keyword None object True True False Country
CustomerID CustomerID True double None float64 True True False CustomerID
Description Description True keyword None object True True False Description
InvoiceDate InvoiceDate True keyword None object True True False InvoiceDate
InvoiceNo InvoiceNo True keyword None object True True False InvoiceNo
Quantity Quantity True long None int64 True True False Quantity
StockCode StockCode True keyword None object True True False StockCode
UnitPrice UnitPrice True double None float64 True True False UnitPrice
Operations:
tasks: [('tail': ('sort_field': '_doc', 'count': 2)), ('head': ('sort_field': '_doc', 'count': 2)), ('tail': ('sort_field': '_doc', 'count': 2))]
size: 2
sort_params: {'_doc': 'desc'}
_source: ['Country', 'CustomerID', 'Description', 'InvoiceDate', 'InvoiceNo', 'Quantity', 'StockCode', 'UnitPrice']
body: {}
post_processing: [('sort_index'), ('head': ('count': 2)), ('tail': ('count': 2))]
[13]:
df.tail(2)
[13]:
| 国家 | 客户 ID | ... | 库存代码 | 单价 | |
|---|---|---|---|---|---|
| 14998 | 英国 | 17419.0 | ... | 21773 | 1.25 |
| 14999 | 英国 | 17419.0 | ... | 22149 | 2.10 |
2 行 × 8 列
选择列#
您还可以传递一个列列表来按指定顺序从数据帧中选择列。
[14]:
df[['Country', 'InvoiceDate']].head(5)
[14]:
| 国家 | 发票日期 | |
|---|---|---|
| 0 | 英国 | 2010-12-01 08:26:00 |
| 1 | 英国 | 2010-12-01 08:26:00 |
| 2 | 英国 | 2010-12-01 08:26:00 |
| 3 | 英国 | 2010-12-01 08:26:00 |
| 4 | 英国 | 2010-12-01 08:26:00 |
5 行 × 2 列
布尔索引#
我们还允许您使用布尔索引过滤数据帧。在幕后,布尔索引映射到一个 terms 查询,然后传递给 Elasticsearch 以过滤索引。
[15]:
# the construction of a boolean vector maps directly to an elasticsearch query
print(df['Country']=='Germany')
df[(df['Country']=='Germany')].head(5)
{'term': {'Country': 'Germany'}}
[15]:
| 国家 | 客户 ID | ... | 库存代码 | 单价 | |
|---|---|---|---|---|---|
| 1109 | 德国 | 12662.0 | ... | 22809 | 2.95 |
| 1110 | 德国 | 12662.0 | ... | 84347 | 2.55 |
| 1111 | 德国 | 12662.0 | ... | 84945 | 0.85 |
| 1112 | 德国 | 12662.0 | ... | 22242 | 1.65 |
| 1113 | 德国 | 12662.0 | ... | 22244 | 1.95 |
5 行 × 8 列
我们还可以使用一个值列表来过滤数据帧。
[16]:
print(df['Country'].isin(['Germany', 'United States']))
df[df['Country'].isin(['Germany', 'United Kingdom'])].head(5)
{'terms': {'Country': ['Germany', 'United States']}}
[16]:
| 国家 | 客户 ID | ... | 库存代码 | 单价 | |
|---|---|---|---|---|---|
| 0 | 英国 | 17850.0 | ... | 85123A | 2.55 |
| 1 | 英国 | 17850.0 | ... | 71053 | 3.39 |
| 2 | 英国 | 17850.0 | ... | 84406B | 2.75 |
| 3 | 英国 | 17850.0 | ... | 84029G | 3.39 |
| 4 | 英国 | 17850.0 | ... | 84029E | 3.39 |
5 行 × 8 列
我们还可以组合布尔向量来进一步过滤数据帧。
[17]:
df[(df['Country']=='Germany') & (df['Quantity']>90)]
[17]:
| 国家 | 客户 ID | ... | 库存代码 | 单价 |
|---|
0 行 × 8 列
使用此示例,让我们看看 Eland 如何将此布尔过滤器转换为 Elasticsearch bool 查询。
[18]:
print(df[(df['Country']=='Germany') & (df['Quantity']>90)].es_info())
es_index_pattern: online-retail
Index:
es_index_field: _id
is_source_field: False
Mappings:
capabilities:
es_field_name is_source es_dtype es_date_format pd_dtype is_searchable is_aggregatable is_scripted aggregatable_es_field_name
Country Country True keyword None object True True False Country
CustomerID CustomerID True double None float64 True True False CustomerID
Description Description True keyword None object True True False Description
InvoiceDate InvoiceDate True keyword None object True True False InvoiceDate
InvoiceNo InvoiceNo True keyword None object True True False InvoiceNo
Quantity Quantity True long None int64 True True False Quantity
StockCode StockCode True keyword None object True True False StockCode
UnitPrice UnitPrice True double None float64 True True False UnitPrice
Operations:
tasks: [('boolean_filter': ('boolean_filter': {'bool': {'must': [{'term': {'Country': 'Germany'}}, {'range': {'Quantity': {'gt': 90}}}]}}))]
size: None
sort_params: None
_source: ['Country', 'CustomerID', 'Description', 'InvoiceDate', 'InvoiceNo', 'Quantity', 'StockCode', 'UnitPrice']
body: {'query': {'bool': {'must': [{'term': {'Country': 'Germany'}}, {'range': {'Quantity': {'gt': 90}}}]}}}
post_processing: []
聚合和描述性统计#
让我们开始向我们的数据提出一些问题,并使用 Eland 来获得答案。
有多少个不同的国家?
[19]:
df['Country'].nunique()
[19]:
16
订购产品的总和是多少?
[20]:
df['Quantity'].sum()
[20]:
111960
显示 qunatity 和 unit_price 字段的总和、平均值、最小值和最大值
[21]:
df[['Quantity','UnitPrice']].agg(['sum', 'mean', 'max', 'min'])
[21]:
| 数量 | 单价 | |
|---|---|---|
| 总计 | 111960.000 | 61548.490000 |
| 平均数 | 7.464 | 4.103233 |
| 最大值 | 2880.000 | 950.990000 |
| 最小值 | -9360.000 | 0.000000 |
给我整个数据帧的描述性统计信息
[22]:
# NBVAL_IGNORE_OUTPUT
df.describe()
[22]:
| 客户 ID | 数量 | 单价 | |
|---|---|---|---|
| 计数 | 10729.000000 | 15000.000000 | 15000.000000 |
| 平均数 | 15590.776680 | 7.464000 | 4.103233 |
| 标准差 | 1764.189592 | 85.930116 | 20.106214 |
| 最小值 | 12347.000000 | -9360.000000 | 0.000000 |
| 25% | 14225.913815 | 1.000000 | 1.336010 |
| 50% | 15668.124797 | 2.423796 | 2.396465 |
| 75% | 17195.974646 | 7.403795 | 4.282239 |
| 最大值 | 18239.000000 | 2880.000000 | 950.990000 |
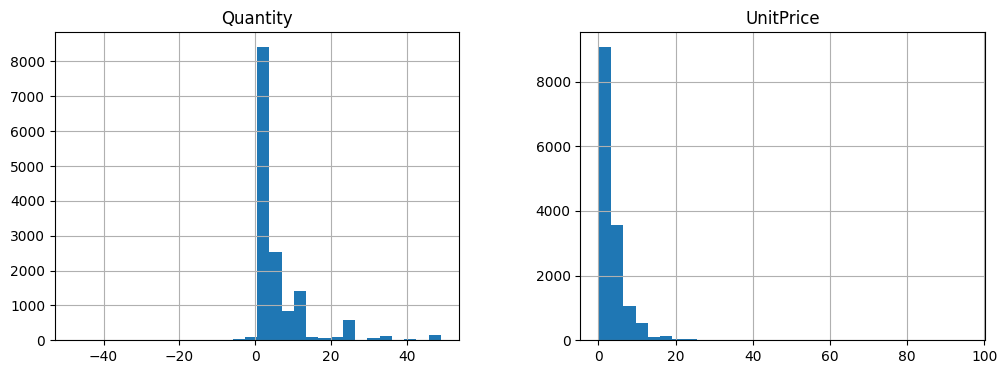
显示数值列的直方图
[23]:
df[(df['Quantity']>-50) &
(df['Quantity']<50) &
(df['UnitPrice']>0) &
(df['UnitPrice']<100)][['Quantity', 'UnitPrice']].hist(figsize=[12,4], bins=30)
plt.show()
[24]:
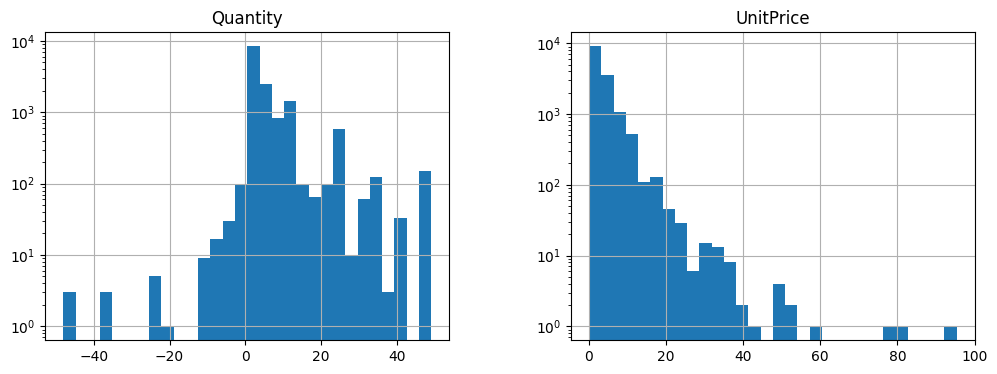
df[(df['Quantity']>-50) &
(df['Quantity']<50) &
(df['UnitPrice']>0) &
(df['UnitPrice']<100)][['Quantity', 'UnitPrice']].hist(figsize=[12,4], bins=30, log=True)
plt.show()
[33]:
filter_quantity_price = df[(df['Quantity'] > 50) & (df['UnitPrice'] < 100)]
print(filter_quantity_price)
Country CustomerID ... StockCode UnitPrice
46 United Kingdom 13748.0 ... 22086 2.55
83 United Kingdom 15291.0 ... 21733 2.55
96 United Kingdom 14688.0 ... 21212 0.42
102 United Kingdom 14688.0 ... 85071B 0.38
176 United Kingdom 16029.0 ... 85099C 1.65
... ... ... ... ... ...
14784 United Kingdom 15061.0 ... 22423 10.95
14785 United Kingdom 15061.0 ... 22075 1.45
14788 United Kingdom 15061.0 ... 17038 0.07
14974 United Kingdom 14739.0 ... 21704 0.72
14980 United Kingdom 14739.0 ... 22178 1.06
[258 rows x 8 columns]
算术运算#
数值
[34]:
df['Quantity'].head()
[34]:
0 6
1 6
2 8
3 6
4 6
Name: Quantity, dtype: int64
[ ]:
df['UnitPrice'].head()
0 2.55
1 3.39
2 2.75
3 3.39
4 3.39
Name: UnitPrice, dtype: float64
[ ]:
product = df['Quantity'] * df['UnitPrice']
/usr/local/lib/python3.10/dist-packages/eland/field_mappings.py:715: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
self._mappings_capabilities = self._mappings_capabilities.append(
[ ]:
product.head()
0 15.30
1 20.34
2 22.00
3 20.34
4 20.34
dtype: float64
字符串连接
[ ]:
df['Country'] + df['StockCode']
/usr/local/lib/python3.10/dist-packages/eland/field_mappings.py:715: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
self._mappings_capabilities = self._mappings_capabilities.append(
0 United Kingdom85123A
1 United Kingdom71053
2 United Kingdom84406B
3 United Kingdom84029G
4 United Kingdom84029E
...
14995 United Kingdom72349B
14996 United Kingdom72741
14997 United Kingdom22762
14998 United Kingdom21773
14999 United Kingdom22149
Length: 15000, dtype: object